Die Translation ist der Prozess der Proteinbiosynthese, bei dem das messenger-RNA-Transkript in ein Protein übersetzt wird. Dieser Prozess ist in drei Phasen unterteilt: Initiation, Elongation und Termination. Die Translation findet an den Ribosomen statt. Das sind große Komplexe aus Proteinen und ribosomaler RNA RNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA ( rRNA rRNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA). Das Ribosom „liest“ die mRNA mRNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA und bindet transfer-RNAs (tRNAs), die jeweils mit einer bestimmten Aminosäure Aminosäure Grundlagen der Aminosäuren assoziiert sind. Die Peptidyltransferase verknüpft die gebundenen Aminosäuren anschließend zu einer Polypeptidkette. Die Translation kann auf mehreren Ebenen reguliert werden. Eine Form der Translationsregulation ist die RNA-Interferenz. An diesem Prozess sind kleine Abschnitte doppelsträngiger RNA RNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA beteiligt, die die Translation von mRNAs hemmen.
Kostenloser
Download
Lernleitfaden
Medizin ➜

Struktur von RNA und DNA
Bild von Lecturio.Der genetische Code ist die Art und Weise, wie die Basensequenz der DNA DNA Die Desoxyribonukleinsäure – Aufbau, Struktur und verschiedene Arten der DNA oder RNA RNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA in eine Aminosäuresequenz übersetzt wird.
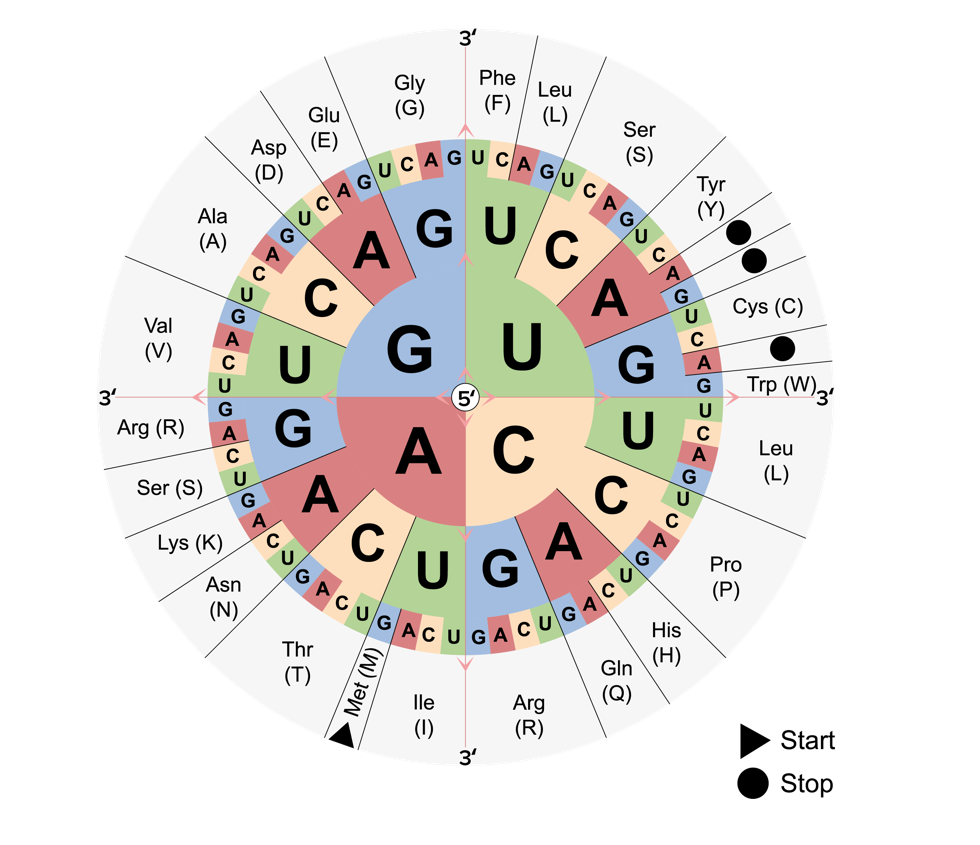
Genetischer Code:
Gelesen wird die Code-Sonne von der Mitte aus zum Rand, um festzustellen, für welche Aminosäuren jedes der 64 Codons kodiert. Start- und Stoppcodons sind gekennzeichnet.
Die Translation der mRNA mRNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA in ein Protein erfolgt durch die Ribosomen und tRNAs.
tRNAs transportieren spezifische Aminosäuren zu den Ribosomen und binden über komplementäre Anticodons an die mRNA mRNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA. Die Aminosäuren werden zu einer Polypeptidkette verknüpft.

Sekundärstruktur der transfer-RNA (tRNA). Es handelt sich um ein sehr kleines RNA-Molekül, sodass die gesamte Sequenz abgebildet ist.
Bild von Lecturio.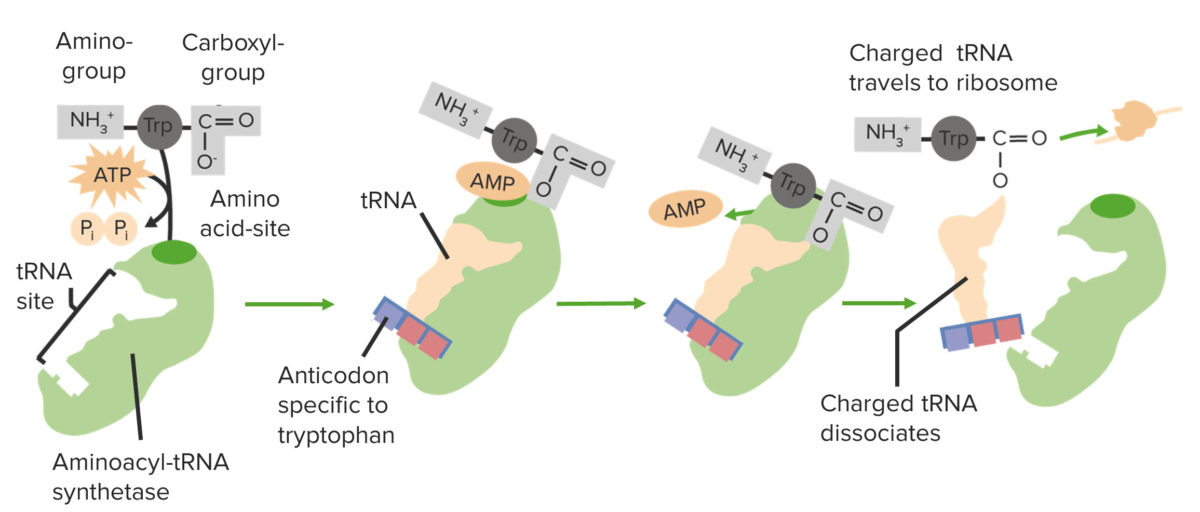
Beladen der tRNA durch die Aminoacyl-tRNA-Synthetase
Bild von Lecturio.Die Translation findet an den Ribosomen statt. Es handelt sich dabei um katalytische Komplexe, die aus ribosomaler RNA RNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA und Proteinen bestehen. Innerhalb des ribosomalen Komplexes werden tRNAs gebunden und die mRNA mRNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA in ein Polypeptid übersetzt.

Ribosomenstruktur: Die große Untereinheit mit A-, P- und E-Bindungsstellen für beladene tRNAs. Die kleine Untereinheit befindet sich unterhalb der mRNA.
Bild von Lecturio.| Prokaryoten | Eukaryoten | |
|---|---|---|
| Größe der kleinen Untereinheit | 30 S | 40 S |
| Größe der großen Untereinheit | 50 S | 60 S |
| Anzahl der Proteine Proteine Proteine und Peptide | 52 | 88 |
| Anzahl der rRNAs | 3 | 4 |
| Größe der homologen rRNAs in der kleinen Untereinheit | 16 S | 18 S |
| Größen der homologen rRNAs in der großen Untereinheit |
|
|
| Größe der rRNA rRNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA in der großen Untereinheit ohne prokaryontisches Homolog | 5,8 S |
Die Initiation der Translation beinhaltet die Zusammenlagerung des Ribosoms an der mRNA mRNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA in richtiger Ausrichtung sowie das Auffinden des Startcodons.
Nach Bindung an das 5′-Ende der mRNA mRNA Die Ribonukleinsäure – Aufbau, Struktur und verschiedene Arten von RNA beginnt die kleine Untereinheit mit der Suche nach dem Startcodon.

Zusammenlagerung eines Ribosoms
fMet: Formylmethionin

Elongationszyklus
Bild von Lecturio.
Bildung einer Peptidbindung innerhalb des Ribosoms
Bild von Lecturio.
Durch die Translokation des Ribosoms gelangt die „leere“ tRNA zur E-Stelle und verlässt das Ribosom
Bild von Lecturio
Wobble-Paarung
Bild von Lecturio.
Bildung einer Peptidbindung zwischen zwei Aminosäuren
Bild von Lecturio.Die Translation endet, wenn das Ribosom ein Stopcodon erreicht.

Termination der Translation
Bild von Lecturio.Die Translation kann auf Ebene der Initiation, Elongation oder Termination reguliert werden. Die Regulation erfolgt überwiegend durch die Hoch- und Herunterregulierung von Initiations-, Elongations- und Terminationsfaktoren. Weitere Regulationsmechanismen der Translation sind die RNA-Interferenz, alternatives Spleißen und RNA-Editing.
RNA-Interferenz (RNAi) ist ein Mechanismus der Hemmung der Translation durch Wechselwirkungen von mRNA-Molekülen mit kleinen doppelsträngigen RNA-Molekülen.

RNA-Interferenz über das RISC und eine miRNA
Bild von Lecturio.
Alternatives Spleißen:
Durch alternatives Spleißen können verschiedene Proteine aus derselben mRNA hergestellt werden.


















